2021寒假实训大数据分析电商平台
一、环境安装
1.1 新建虚拟机
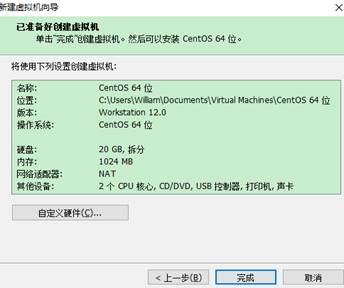
实训的项目主要是进行大数据的实训,所以需要按照Linux,使用VMware Workstation作为虚拟机安装Linux系统,创建虚拟机,步骤如下:

下一步
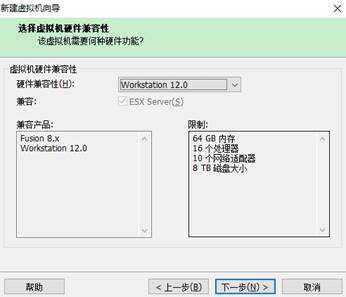
下一步
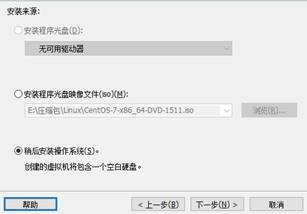
下一步
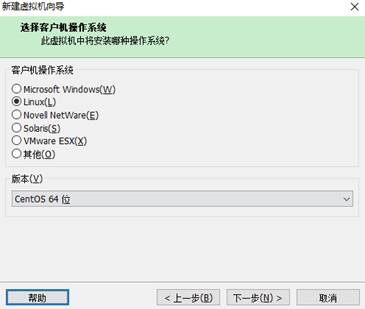
下一步
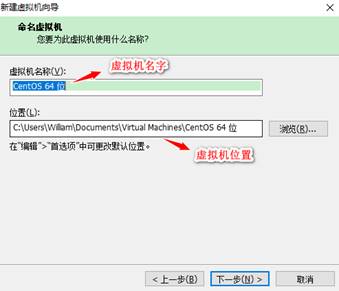
下一步
下一步
下一步
下一步
下一步
下一步
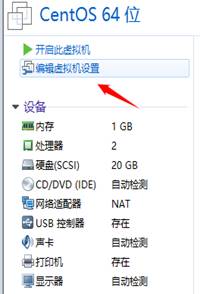
接下来,点击编辑虚拟机,需要找到Linux的IOS文件
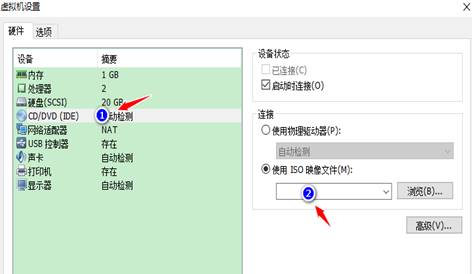
找到镜像文件之后,接下来就是安装Linux系统,选择开启虚拟机,虚拟机进行加载Linux进行安装。
1.2 安装Linux的镜像
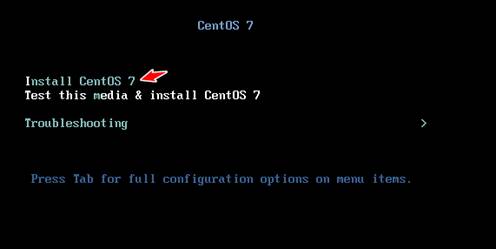
选择语言
下一步

设置密码

安装好之后,进行重启
重启之后,进行登录,输入用户名和密码
1.3 远程登录工具MobaXterm
MobaXterm_Portable_v20.3
可连接虚拟机操作文件 编写命令
连接虚拟机需要知道虚拟机ip地址
在虚拟机中输入ifconfig -a命令进行查找
找不到ifconfig命令,首先查找yum search ifconfig

之后就可以使用
要进行后面的操作,我们需要修改几个配置,关闭防火墙,并禁止开机启动。
查看防火墙状态: systemctl status firewalld
执行关闭命令: systemctl stop firewalld
执行开机禁用防火墙自启命令:systemctl disable firewalld
还有进行主机名的修改:vi /etc/hosts或vi /etc/hostname
1.4 安装JDK及相应准备工作
因为开发需要JDK,所以进行JDK的安装,先在根目录下创建两个目录,作为后期环境的使用:mkdir tools 和 mkdir training,一个是作为上传工具的目录,一个是作为安装的目录。
使用工具上述工具将JDK进行上传到tools目录下,然后进行解压
tar -zvxf /tools/jdk-7u80-linux-x64.tar.gz -C /tarining/
配置环境变量:
vi ~/.bash_profile
添加如下信息
1 | |

让环境变量生效
source ~/.bash_profile
验证jdk是否安装成功
java -version

二、CentOS7下MySQL-5.7使用yum方式安装:
1、安装MySQL YUM源到本地
1 | |
2、检查 mysql 源是否安装成功
1 | |
安装成功后会看到如下:
!mysql-connectors-community/x86_64 MySQL Connectors Community 153
!mysql-tools-community/x86_64 MySQL Tools Community 110
!mysql57-community/x86_64 MySQL 5.7 Community Server 4243、使用 yum install 命令安装
1 | |
4、安装完毕后,启动MySQL数据库
1 | |
5、查看MySQL的启动状态
1 | |
6、设置开机自启动
1 | |
7、重载所有修改过的配置文件
1 | |
8、修改root账户默认密码
mysql 安装完成之后,生成的默认密码在 /var/log/mysqld.log 文件中。使用 grep 命令找到日志中的密码。
执行:
1 | |
比如:
A temporary password is generated for root@localhost: WMYu.#o8o#309、修改密码
使用mysql -uroot -p 回车, 注意密码改为:Sjm@!_123456 输入:
1 | |
10、配置root用户远程登录及添加远程登录用户
默认只允许root帐户在本地登录,如果要在其它机器上连接mysql,两种方式:
1)设置root用户允许远程登录:
执行:
1 | |
2)可以添加一个允许远程连接的普通帐户
执行:1 | |
12、设置默认编码为 utf8
mysql 安装后默认不支持中文,需要修改编码。
修改 /etc/my.cnf 配置文件,在相关节点(没有则自行添加)下添加编码配置,如下:
执行:vi /etc/my.cnf
在文件的末尾添加如下信息:
1 | |
CentOS7下MySQL-5.7使用yum方式卸载:
1、停止MySQL
命令:systemctl stop mysqld
2、查看已安装的mysql
命令:rpm -qa | grep -i mysql
3、卸载mysql,依次卸载第2步骤所列出的有关MySQL的安装包,如
命令:yum remove -y mysql-community-server-5.6.36-2.el7.x86_64
4、删除mysql相关目录
1)使用命令查看mysql相关的文件目录:find / -name mysql
2)依次删除所查到的目录,命令:rm -rf /xxx/xxx/mysql
三、CentOS7下Nginx的安装:
1、编写安装脚本:nginx_install.sh,添加如下内容:
1 | |
2、赋予nginx_intall.sh执行权限:
1 | |
3、安装nginx,进入到nginx_intall.sh脚本所在目录,执行:
1 | |
4、编写启动nginx的脚本nginx_start.sh,执行 vi nginx_start.sh添加如下内容:
1 | |
5、启动nginx,执行
1 | |
6、验证nginx是否启动成功:
1 | |
成功信息:
1 | |
7、编写停止nginx脚本,执行vi nginx_stop.sh ,添加如下内容:
1 | |
8、停止nginx,执行
1 | |
9、编写热加载nginx脚本,执行vi nginx_reload.sh ,添加如下内容:
1 | |
10、重新加载nginx,执行:
1 | |
四、部署前端网站到nginx下
1、上传电商网站OnlineShop文件夹到/training/nginx/html/目录下,
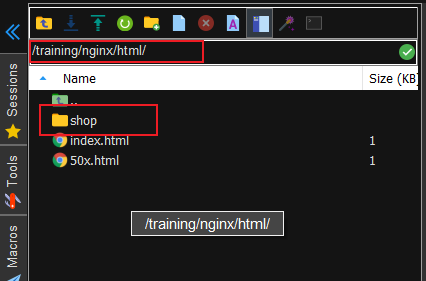
将OnlineShop文件夹重命名为shop
1 | |
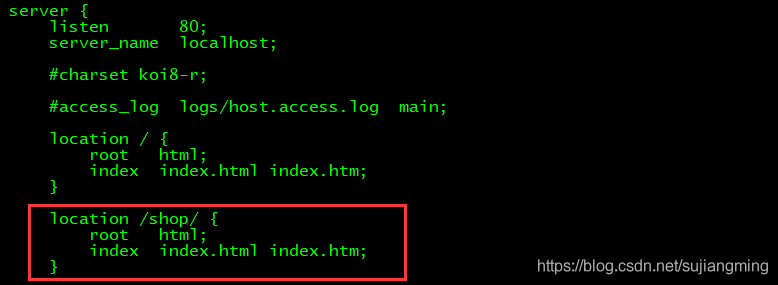
2、修改nginx配置文件nginx.conf,执行:
1 | |
添加如下内容:1 | |
3、重新记载nginx,执行:
1 | |
4、验证:在浏览器中验证下是否可以访问到网站,输入:
1 | |
5、效果如下: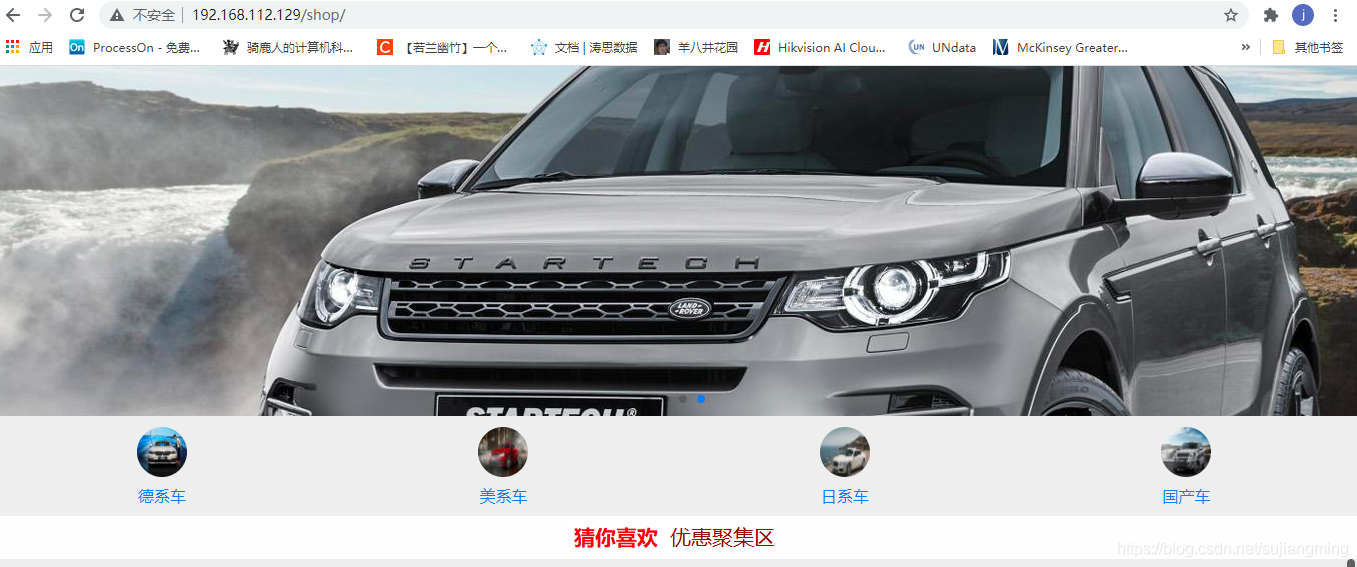
五、Tomcat的安装
1、下载tomcat-8.5.40,到官网上下
2、安装tomcat
1)上传tomcat到/tools目录下
2)解压安装:1 | |
3)配置环境变量 vi ~/.bash_profile1 | |
4)生效:1 | |
5)启动1 | |
6)验证,在浏览器输入: http://192.168.215.131:8080/
或者在命令行里面输入:netstat -anop|grep 8080 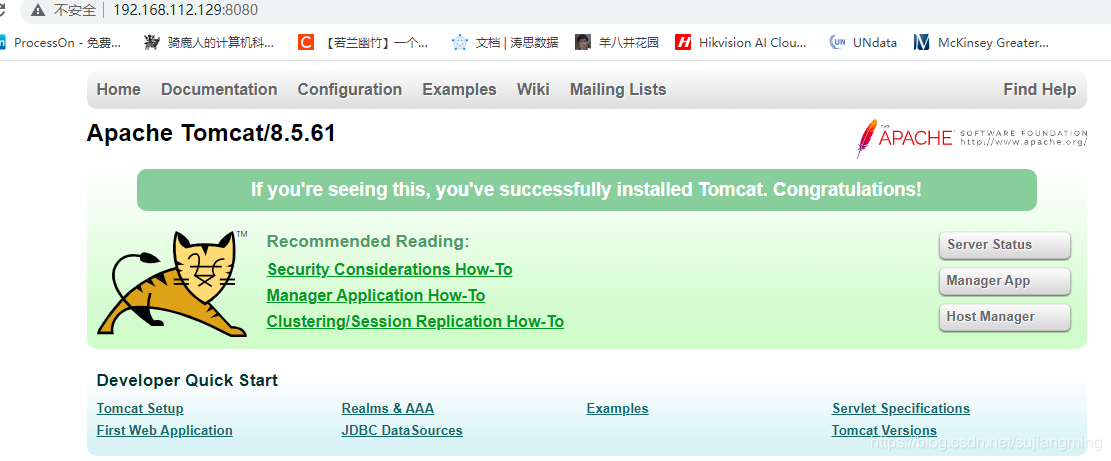
六、电商后台系统部署到Linux服务器上
- 将代码导入到eclipse或者idea中
- 将代码中的接口地址、数据库链接地址等修改成服务器地址,具体需要修改的代码如下:
1 | |
- 选择export->war
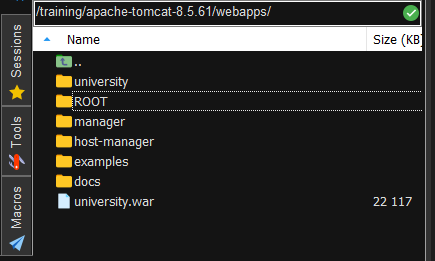
- 上传war至Linux服务器的Tomcat安装目录下(见下图)
- 启动或重启Tomcat
- 配置Tomcat支持UTF-8字符集
由于后台项目页面部分采用了html和jsp结合嵌套的方式,即在jsp中嵌套了html代码段,会存在html代码段显示中文乱码的问题,故需要做配置
1)修改tomcat/conf目录下的server.xml,添加URIEncoding=“UTF-8”配置项,配置位置如下:
1 | |
2)修改tomcat/conf/web.xml,在 <servlet>节点中添加如下内容:1 | |
3)先删除tomcat下的webapp/项目/所有html页面,再重新新建并添加对应的内容
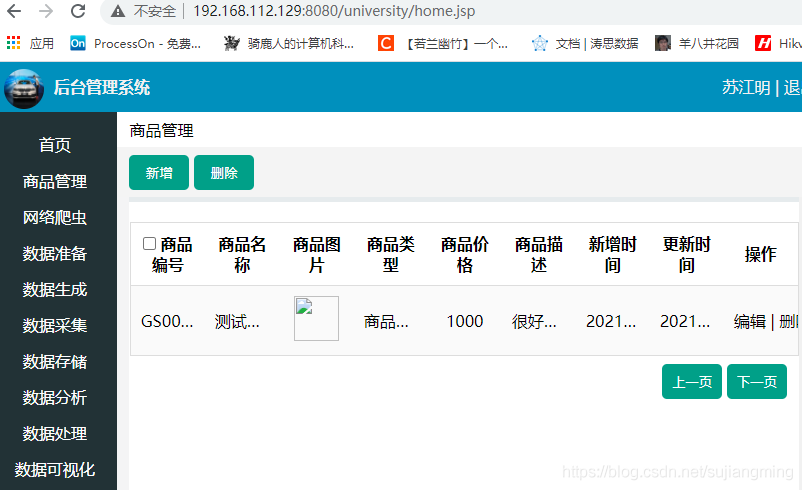
4)启动Tomcat6、打开浏览器进行验证:
七、AB压测(httpd)安装
1. 安装httpd
1
yum install -y httpd
配置httpd,修改端口号为81,配置如下:
1
vi /etc/httpd/conf/httpd.conf修改内容如下:
1
2#Listen 80
Listen 81启动服务
1
2systemctl enable httpd # 开机自启动
systemctl start httpd # 启动httpd查看启动状态
1
systemctl status httpd编写压测脚本ab_test.sh,内容可自行修改,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#!/bin/bash
n=`cat url.txt | wc -l`
for ((i=1;i<=$n;i++))
do
echo $i
url=`shuf -n1 url.txt`
r=`shuf -i 6-100 -n 1`
c=`shuf -i 1-5 -n 1`
echo $url
echo $r
echo $c
##将测试的结果写入到test_ab.log >> results.log &
ab -n $r -c $c $url >> results.log &
done测试结果说明
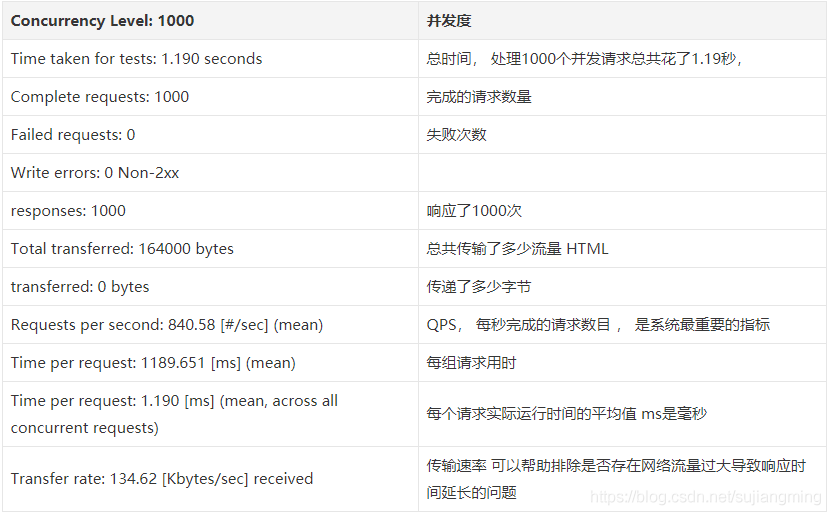
八、Hadoop安装与配置
8.1 安装Hadoop
1、把上传到tools目录下的Hadoop进行解压
1 | |
2、配置环境变量:
1 | |
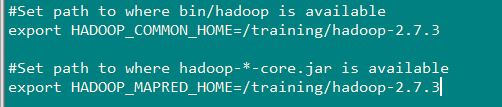
添加如下信息:
1 | |
3、 让环境变量生效:
1 | |

验证是否生效:
执行:hdfs 或者hadoop 有相关信息出现即可
8.2 搭建Hadoop伪分布环境
特点:具备HDFS全部功能
HDFS:NameNode + DataNode
Yarn:ReourceManager + NodeManager
1、配置:hadoop-env.sh
vi hadoop-env.sh
配置Java环境变量:
export JAVA_HOME=/training/jdk1.8.0_171

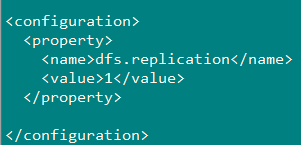
2、配置:hdfs-site.xml
vi /training/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
hdfs-site.xml:原则是:一般有几个数据节点就配置几个,但是最多不能超多3
1 | |
3、配置:core-site.xml
需要提前新建一个tmp文件夹
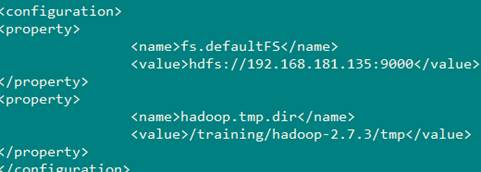
vi /training/hadoop-2.7.3/etc/hadoop/core-site.xml
1 | |
4、配置:mapper-site.xml
这个文件事先是不存在的,需要复制一份
cp /training/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template /training/hadoop-2.7.3/etc/hadoop/mapred-site.xml
vi /training/hadoop-2.7.3/etc/hadoop/mapper-site.xml
1 | |

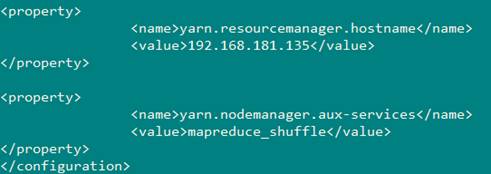
5、配置:yarn-site.xml
vi /training/hadoop-2.7.3/etc/hadoop/mapper-site.xml
1 | |
8.3 设置免密码登录
ssh-keygen -t rsa
ssh-copy-id 192.168.91.130

8.4 验证Hadoop
格式化:HDFS(NameNode)
hdfs namenode -format
启动hadoop环境
start-all.sh
访问:web界面进行验证
HDFS:http://192.168.181.135:50070
Yran:http:// 192.168.181.135:8088
停止:
stop-all.sh


九、Flume的安装与配置
上传flume到/tools目录下
解压安装
1
tar -zvxf apache-flume-1.9.0-bin.tar.gz -C /training/配置环境变量,并让环境变量生效
1
vi ~/.bash_profile1
2export FLUME_HOME=/trainin~g/apache-flume-1.9.0-bin
export PATH=$PATH:$FLUME_HOME/bin将hadoop-2.7.3安装路径下的依赖的jar导入到/apache-flume-1.9.0-bin/lib下:
1
2
3
4
5
6share/hadoop/common/hadoop-common-2.7.3.jar
share/hadoop/common/lib/commons-configuration-1.6.jar
share/hadoop/common/lib/hadoop-auth-2.7.3.jar
share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar
share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar
share/hadoop/common/lib/commons-io-2.4.jar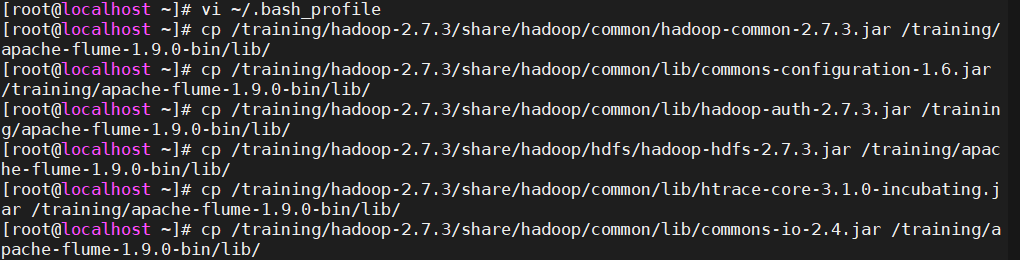
验证
1
bin/flume-ng version
配置Flume HDFS Sink:
在/training/apache-flume-1.7.0-bin/conf/新建一个flume-hdfs.conf
添加如下内容:(注意改ip地址)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45# define the agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# define the source
#上传目录类型
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/training/nginx/logs/flumeLogs
#定义自滚动日志完成后的后缀名
a1.sources.r1.fileSuffix=.FINISHED
#根据每行文本内容的大小自定义最大长度4096=4k
a1.sources.r1.deserializer.maxLineLength=4096
# define the sink
a1.sinks.k1.type = hdfs
#上传的文件保存在hdfs的/flumeLogs目录下
a1.sinks.k1.hdfs.path = hdfs://192.168.91.130:9000/flumeLogs/%y-%m-%d/%H/%M/%S
a1.sinks.k1.hdfs.filePrefix=access_log
a1.sinks.k1.hdfs.fileSufix=.log
a1.sinks.k1.hdfs.batchSize=1000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat= Text
# roll 滚动规则:按照数据块128M大小来控制文件的写入,与滚动相关其他的都设置成0
#为了演示,这里设置成500k写入一次
a1.sinks.k1.hdfs.rollSize= 512000
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.rollInteval=0
#控制生成目录的规则:一般是一天或者一周或者一个月一次,这里为了演示设置10秒
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit= second
#是否使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp=true
#define the channel
a1.channels.c1.type = memory
#自定义event的条数
a1.channels.c1.capacity = 500000
#flume事务控制所需要的缓存容量1000条event
a1.channels.c1.transactionCapacity = 1000
#source channel sink cooperation
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1注意:- 需要先在/training/nginx/logs/创建flumeLogs
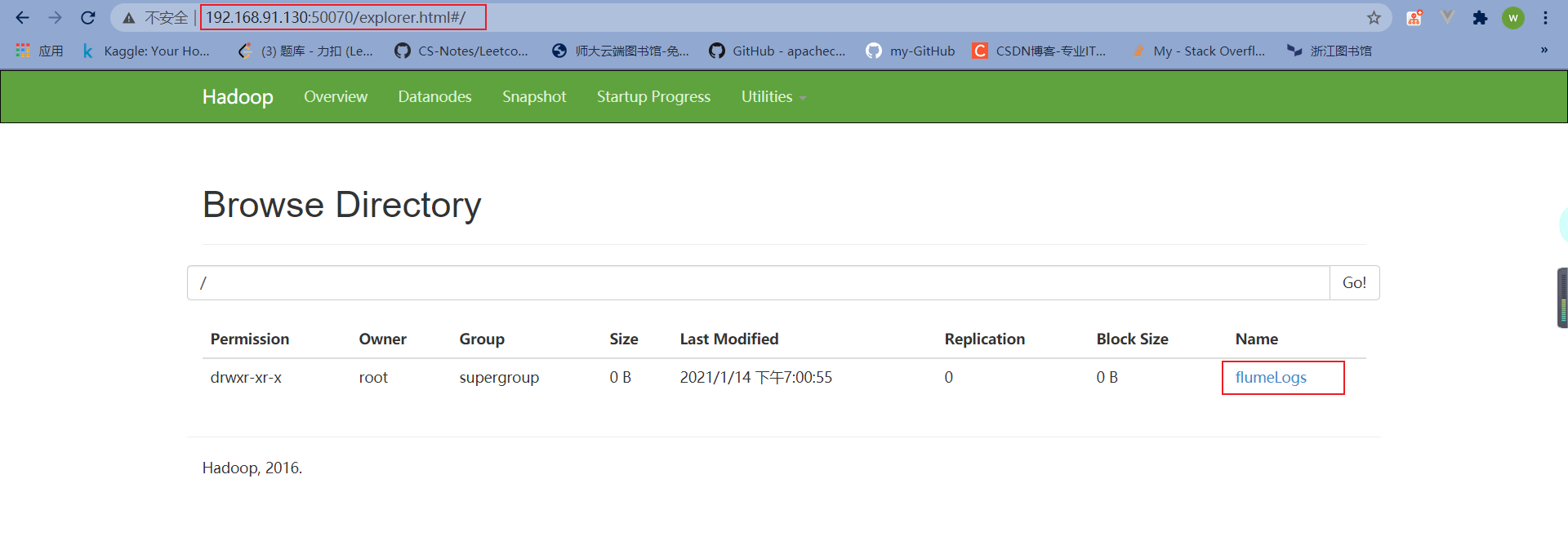
- 需要在hdfs的根目录/下创建flumeLogs
1 | |
创建完成后浏览器输入网址,可以看见刚刚在hdfs中创建的文件
修改conf/flume-env.sh(该文件事先是不存在的,需要复制一份)
复制:1
cp flume-env.template.sh flume-env.sh编辑文件,并设置如下内容:
1
2
3
4#设置JAVA_HOME:
export JAVA_HOME=/training/jdk1.8.0_171
#修改默认的内存:
export JAVA_OPTS="-Xms1024m -Xmx1024m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit"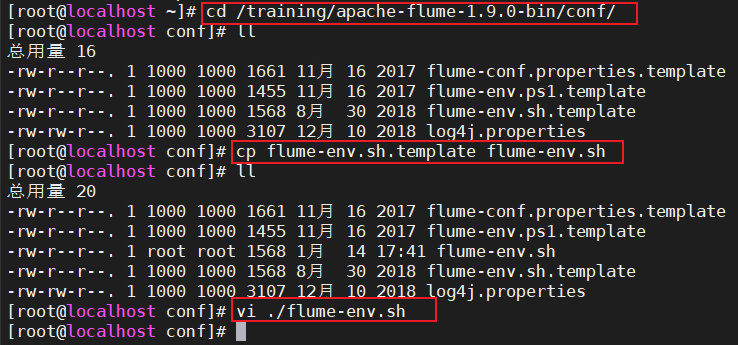
启动flume
测试数据:把 /training/nginx/logs/access.log 复制到
/training/nginx/logs/flumeLogs/access_201904251200.log启动
在/training/apache-flume-1.7.0-bin目录下,执行如下命令进行启动:1
bin/flume-ng agent --conf ./conf/ -f ./conf/flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console到Hadoop的控制台http://bigdata:50070/flumeLogs 查看有没有数据
编写Linux脚本rollingLog.sh,实现/training/nginx/logs/access.log日志的自动滚动到flumeLogs目录下
在~目录下新建rollingLog.sh,并添加如下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23#!/bin/bash
#定义日期格式
dataformat=`date +%Y-%m-%d-%H-%M-%S`
#复制access.log并重命名
cp /training/nginx/logs/access.log /training/nginx/logs/access_$dataformat.log
host=`hostname`
sed -i 's/^/'${host}',&/g' /training/nginx/logs/access_$dataformat.log
#统计日志文件行数
lines=`wc -l < /training/nginx/logs/access_$dataformat.log`
#将格式化的日志移动到flumeLogs目录下
mv /training/nginx/logs/access_$dataformat.log /training/nginx/logs/flumeLogs
#清空access.log的内容
sed -i '1,'${lines}'d' /training/nginx/logs/access.log
#重启nginx , 否则 log can not roll.
kill -USR1 `cat /training/nginx/logs/nginx.pid`
##返回给服务器信息
ls -al /training/nginx/logs/flumeLogs/
编写启动Flume脚本 flume_start.sh,启动Flume
1
2#!/bin/bash
/training/apache-flume-1.9.0-bin/bin/flume-ng agent -c /training/apache-flume-1.9.0-bin/conf/ -f /training/apache-flume-1.9.0-bin/conf/flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console &编写停止Flume脚本 flume_stop.sh,停止Flume
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#!/bin/bash
JAR="flume"
#停止flume函数
echo "begin stop flume process.."
num=`ps -ef|grep java|grep $JAR|wc -l`
echo "当前已经启动的flume进程数:$num"
if [ "$num" != "0" ];then
#正常停止flume
ps -ef|grep java|grep $JAR|awk '{print $2;}'|xargs kill
echo "进程已经关闭..."
else
echo "服务未启动,无须停止..."
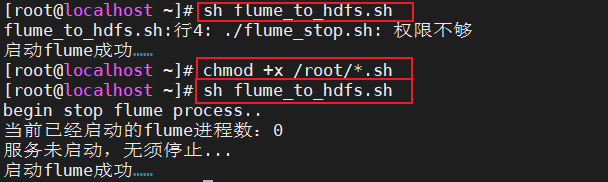
fi编写重启Flume脚本 flume_to_hdfs.sh,综合了前两个脚本
1
2
3
4
5
6
7
8
9#!/bin/bash
#先停止正在启动的flume
./flume_stop.sh
#用法:nohup ./start-dishi.sh >output 2>&1 &
nohup ./flume_start.sh > nohup_output.log 2>&1 &
echo "启动flume成功……"测试(如果权限不够则加权限)
十、MapReduce工程
MapReduce代码编写
(1)创建MapReduce工具
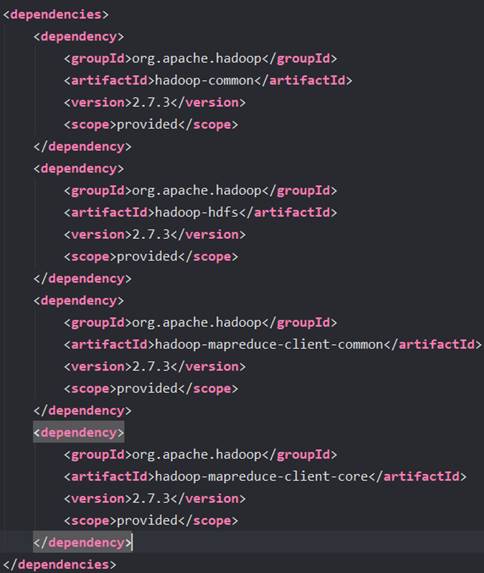
(2)导入Hadoop的依赖包
(3)写代码
导入依赖包
创建类LogMapper类
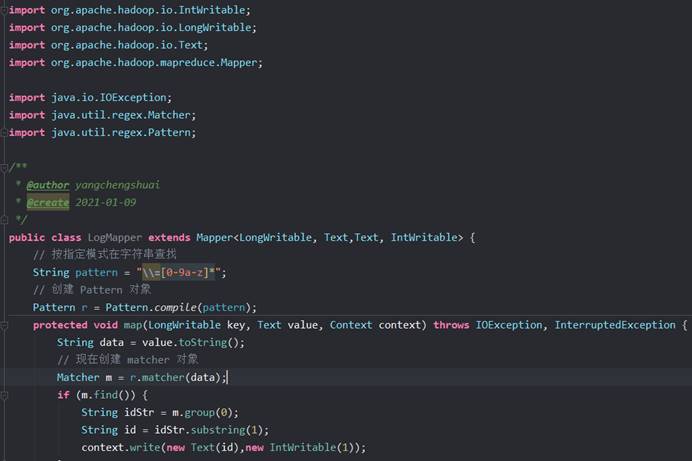
创建LogReducer类
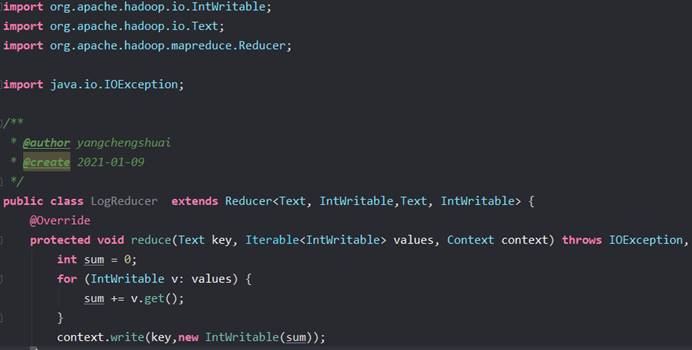
创建LogJob类
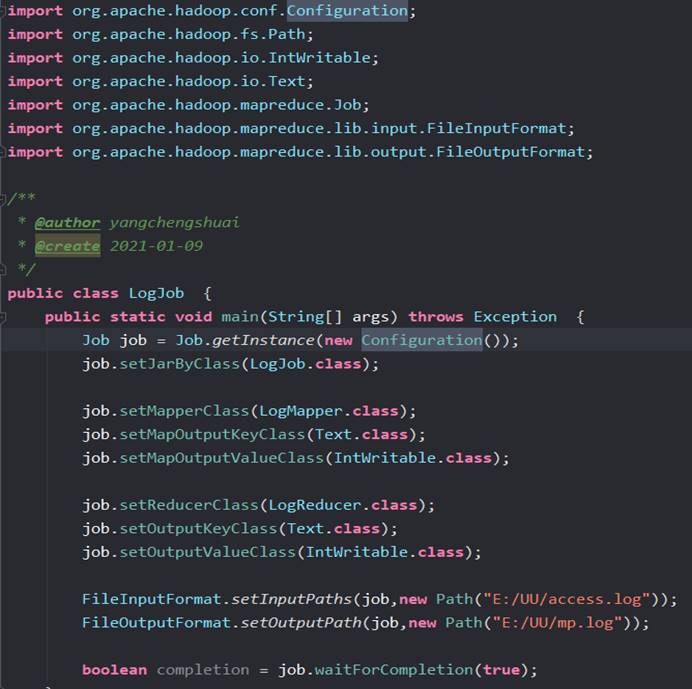
本地运行测试结果正确后,需要对Driver类输入输出部分代码进行修改,具体修改如下
1 | |
打jar包,提交集群运行
为方便操作,编写脚本exec_mr.sh来执行MR程序
1 | |
打包好的上次到HDFS中,进入运行

十一、SQOOP安装配置
Sqoop是Apache旗下一款Hadoop和关系数据服务之间传送数据的工具
12.1 安装
上传sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz到/tools目录下
解压安装
1 | |
添加环境变量:
1 | |
1 | |
让环境生效
1 | |
12.2 配置sqoop文件
修改
1 | |
将出现HCAT_HOME和ACCUMULO_HOME部分内容注释掉.
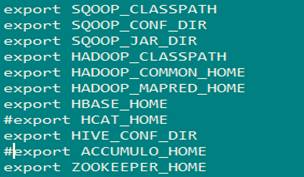
修改sqoop-site.xml和sqoop-env.sh
1 | |
具体配置如下文件所示:
sqoop-site.xml:

sqoop-env.sh:
1 | |
将MySQL数据库的驱动(使用5.x版本,不要使用高版本的)上传到sqoop安装目录下的lib目录下
由于sqoop缺少java-json.jar包进行解析json,也需要上传到sqoop安装目录下的lib目录下

验证
1 | |

创建数据库表t_mr_result,创建语句:
1 | |
编写sqoop从hadoop导出数据到MySQL的脚本sqoop_mysql.sh
修改下面的IP地址和密码
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!