Hadoop入门
一、从Hadoop框架讨论大数据生态
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
1.1 Hadoop是什么
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
1.2 Hadoop发展历史
Lucene–Doug Cutting开创的开源软件,用java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2001年年底成为apache基金会的一个子项目
对于大数量的场景,Lucene面对与Google同样的困难
学习和模仿Google解决这些问题的办法 :微型版Nutch
可以说Google是hadoop的思想之源(Google在大数据方面的三篇论文)
GFS —>HDFS
Map-Reduce —>MR
BigTable —>Hbase
2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,使Nutch性能飙升
2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
名字来源于Doug Cutting儿子的玩具大象

- Hadoop就此诞生并迅速发展,标志这云计算时代来临
1.3 Hadoop三大发行版本
Hadoop 三大发行版本: Apache、Cloudera、Hortonworks
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
1)Cloudera Hadoop
- 2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- 2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
- CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
- Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
2)Hortonworks Hadoop
- 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- 公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
- 雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
- HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
1.4 Hadoop的优势
高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
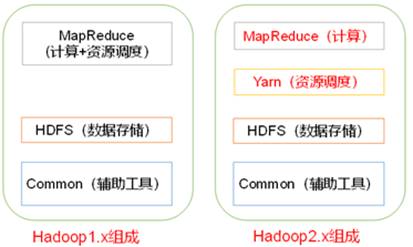
1.5 Hadoop组成
Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
Hadoop MapReduce:一个分布式的离线并行计算框架。
Hadoop YARN:作业调度与集群资源管理的框架。
Hadoop Common:支持其他模块的工具模块。
1、HDFS架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2、YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
3、MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
1.6 大数据生态体系
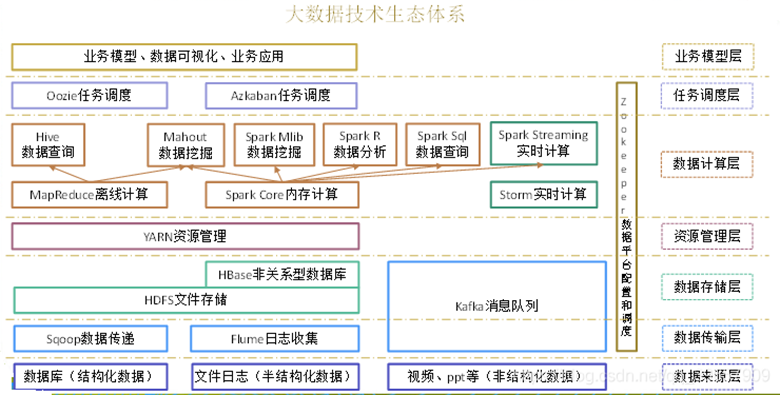
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
支持通过Kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
9)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
10)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
11)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
二、Hadoop环境配置
上传文件需要文件
进入到根目录下,两个目录
mkdir /tools 作为上传安装的文件
mkdir /training 作为后面环境的使用
2.1 修改映射名和配置host文件
我们可以进行修改。通过编辑/etc/hosts文件
vi /etc/hosts


2.2 关闭防火墙
关闭防火墙(CentOS7下)
systemctl stop firewalld.service
systemctl disable firewalld.service
2.3 安装JDK
把上传到tools目录下的JDK进行解压
tar -zvxf jdk-7u80-linux-x64.tar.gz -C /tarining/
配置环境变量:
vi ~/.bash_profile
添加如下信息
1 | |
让环境变量生效
source ~/.bash_profile
验证jdk是否安装成功
java -version

2.4 安装Hadoop
把上传到tools目录下的Hadoop进行解压
tar -zvxf /hadoop-2.7.3.tar.gz -C /training/

cd /training/hadoop-2.7.3/
配置环境变量:
vi ~/.bash_profile
添加如下信息:
1 | |
让环境变量生效:
source ~/.bash_profile
tree -d -L 3 hadoop-2.7.3/ 会列出三级树形结构目录
三、Hadoop运行模式
3.1 参考网址
(1)官方网站:
(2)各个版本归档库地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
(3)hadoop2.7.2版本详情介绍
http://hadoop.apache.org/docs/r2.7.2/
3.2 Hadoop运行模式
本地模式(默认模式):
- 不需要启用单独进程,直接可以运行,测试和开发时使用。
伪分布式模式:
- 等同于完全分布式,只有一个节点。
完全分布式模式:
- 多个节点一起运行。
3.2.1 本地模式测试
- 特点:没有HDFS,只能进行MapReduce计算,而且只操作Linux上的文件
验证下:
1、把上传到tools目录下的Hadoop进行解压
1 | |
2、配置环境变量:
1 | |
添加如下信息:
1 | |
3、 让环境变量生效:
1 | |
测试前需要创建测试目录和测试文件:
1 | |
输入如下内容:
I love Guiyang
I love Guizhou
Guiyang is the capital of Guizhou
保存退出
进入到:mapreduce/目录下
1 | |
执行:~/output 不需要事先存在,存在会报错
1 | |
查看结果:
MapReduce程序的执行结果会默认按照英文单词的字典顺序进行了排序


3.2.2 伪分布模式环境搭建
特点:具备HDFS全部功能
HDFS:NameNode + DataNode
Yarn:ReourceManager + NodeManager
1)分析:
(1)准备1台客户机
(2)安装jdk
(3)配置环境变量
(4)安装hadoop
(5)配置环境变量
(6)配置集群
(7)启动、测试集群增、删、查
(8)在HDFS上执行wordcount案例
2)执行步骤
需要配置hadoop文件如下
1、配置:hadoop-env.sh
1 | |
配置Java环境变量:
1 | |

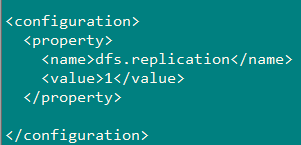
2、配置:hdfs-site.xml
1 | |
hdfs-site.xml:原则是:一般有几个数据节点就配置几个,但是最多不能超多3
1 | |
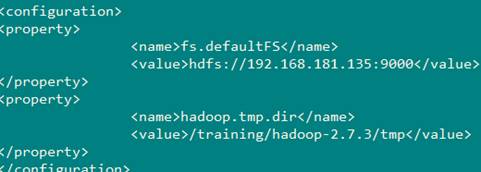
3、配置:core-site.xml
需要提前新建一个tmp文件夹
vi /training/hadoop-2.7.3/etc/hadoop/core-site.xml
1 | |
4、配置:mapper-site.xml
这个文件事先是不存在的,需要复制一份
1 | |
1 | |
1 | |

5、配置:yarn-site.xml
1 | |
1 | |
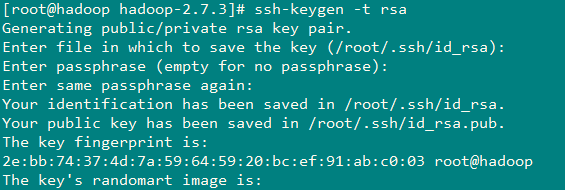
设置免密码登录
1 | |
1 | |
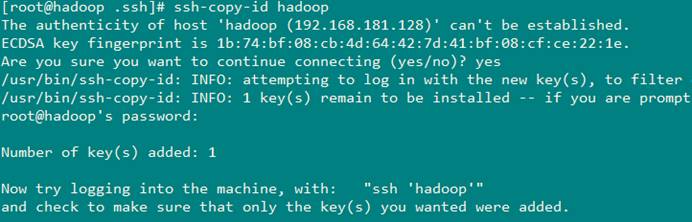
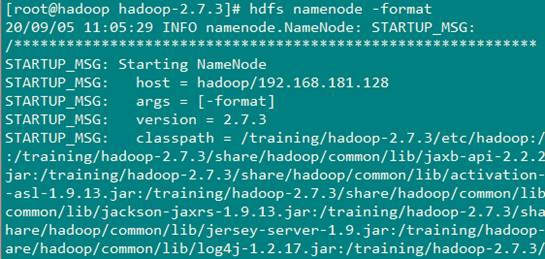
最后验证Hadoop
格式化:HDFS(NameNode)
1 | |
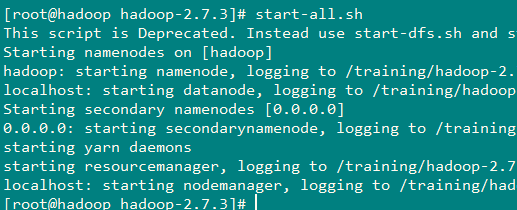
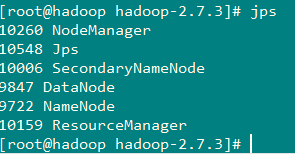
启动hadoop环境
1 | |
访问:web界面进行验证
HDFS:http://192.168.91.130:50070
Yran:http://192.168.91.130:8088
停止:
1 | |
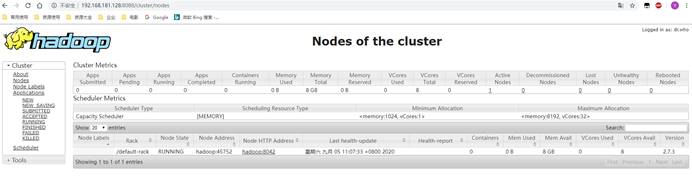
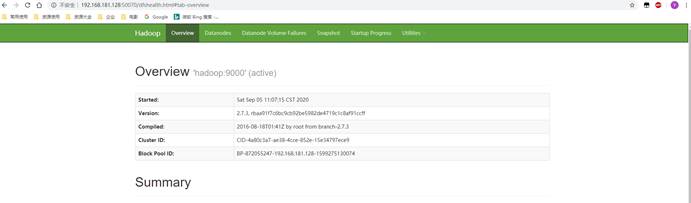
3.2.3 伪分布测试
编辑test.txt文件,写入一个单词。
I have a dream that one day this nation will rise up and live out the true meaning of its creed: “We hold these truths to be self-evident, that all men are created equal.”
I have a dream that one day on the red hills of Georgia, the sons of former slaves and the sons of former slave owners will be able to sit down together at the table of brotherhood.
I have a dream that one day even the state of Mississippi, a state sweltering with the heat of injustice, sweltering with the heat of oppression, will be transformed into an oasis of freedom and justice.
I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character.
I have a dream today!
I have a dream that one day, down in Alabama, with its vicious racists, with its governor having his lips dripping with the words of “interposition” and “nullification” – one day right there in Alabama little black boys and black girls will be able to join hands with little white boys and white girls as sisters and brothers.
I have a dream today!
I have a dream that one day every valley shall be exalted, and every hill and mountain shall be made low, the rough places will be made plain, and the crooked places will be made straight; “and the glory of the Lord shall be revealed and all flesh shall see it together.”
测试需要把文件上传到HDFS上,在HDFS上创建一个目录

将本地的文本上传到HDFS上创建的目录

最后执行

1 | |

查看结果

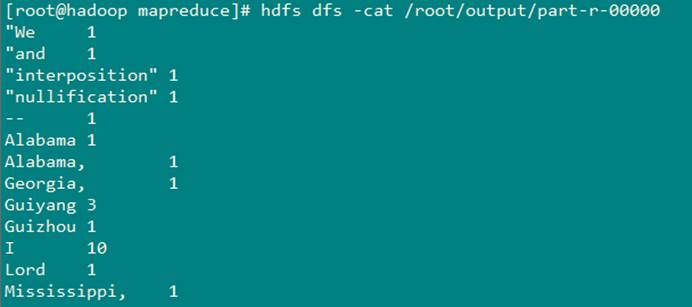
3.2.4 Hadoop全分布模式
分析:
1)准备3台客户机(关闭防火墙、静态ip、主机名称)
2)安装jdk
3)配置环境变量
4)安装hadoop
5)配置环境变量
6)安装ssh
7)配置集群
8)启动测试集群
1)准备工作
1、所有主机安装jdk
2、所有主机都需要关闭防火墙
3、所有主机都需要配置主机名 vi /etc/hosts
4、配置免密码登录(配置两两之间的免密码登录)
所有的机器都需要产生一对密钥:公钥和私钥
1 | |
所有主机需要执行
1 | |
5、保证每台机器的时间是一样的
如果不一样的话,我们在执行MapReduce程序的时候可能会存在问题
解决方案:
1)搭建一个时间同步的服务器,网上很多教程可以使用
2)使用putty工具,可以简单实现这个功能:
date -s 2020-09-01 后面必须敲一个回车
2)在主节点上进行安装配置(hadoop01)
(1)上传hadoop安装包,解决配置环境变量
1 | |
同时设置:hadoop01 hadoop02 hadoop03
1 | |
(*)修改配置文件
vi hadoop-env.sh 设置JDK的路径
hdfs-site.xml:
core-site.xml:
<!–HDFS数据保存在Linux的哪个目录,默认值是Linux的tmp目录 必须配置,否则会报错
/training/hadoop-2.7.3/tmp 必须事先存在–>
mapper-site.xml:
yarn-site.xml:
savles:
hadoop02
hadoop03
(*)格式化nameNode
hdfs namenode -format
日志:
common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
(*)将hadoop01上的hadoop环境复制到hadoop02 hadoop03
scp -r hadoop-2.7.3/ root@hadoop02:/training/
scp -r hadoop-2.7.3/ root@hadoop03:/training/
(*)在主节点(niit01)上启动hdfs
start-all.sh
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!